> “some people have been wrong before” is not a reason to think you know better than the authors of an upcoming Nature article based on a few layperson-targeted paragraphs summarizing the paper from a very high level.
Nor is "this paper is going to appear in Nature" a reason not to wonder whether there might be something that the authors don't know. The whole point of science is that anyone can make an informed critique and self-evaluation of it, with no necessity of depending on a priesthood to interpret it. You can point out the flaws in giantg2's argument https://news.ycombinator.com/item?id=47995899, but neither the venue of the paper, nor the fact that the argument is directed at laypeople in a forum frequented by laypeople, seems to me inherently to indicate such flaws.
> The whole point of science is that anyone can make an informed critique and self-evaluation of it, with no necessity of depending on a priesthood to interpret it.
That's a misinterpretation:
> anyone can
(Of course nothing stops them, but I don't think that's your point.)
> anyone can make an informed critique and self-evaluation of it, with no necessity of depending on a priesthood to interpret it.
Science is specifically not the wisdom of the crowds - that is pre-scientific. It is the wisdom of emprical facts, which are usually so complex and voluminous that it takes great expertise to understand and interpret them. Science is not democratic - your opinion is worthless and does not deserve consideration unless you can demonstrate otherwise.
You don't have to be in the priesthood, but it's tough to have the expertise otherwise, and then tough to stay outside the priesthood.
"'In matters of science,' Galileo wrote, 'the authority of thousands is not worth the humble reasoning of one single person.'" ("In questioni di scienza L'autorità di
mille non vale l'umile ragionare di un singolo." The source was not able to verfy its provenance, however.)
Your reading of my comment seems perfectly charitable, but it also seems to find more in my comment than what I said.
> > anyone can make an informed critique and self-evaluation of it, with no necessity of depending on a priesthood to interpret it.
> Science is specifically not the wisdom of the crowds - that is pre-scientific. It is the wisdom of emprical facts, which are usually so complex and voluminous that it takes great expertise to understand and interpret them. Science is not democratic - your opinion is worthless and does not deserve consideration unless you can demonstrate otherwise.
I did not say that science is democratic, nor that the validity of a scientific fact is determined by the crowds, but rather that anyone can make an informed critique and self-evaluation. 'Can' is perhaps too strong a word; to do this is a skill that usually requires considerable background and training.
Here I think that one must distinguish between the sociology of science and the ideal of science. In the sociology of science, reputation matters, authority is often deferred to, and an amateur will have a tough time getting a serious hearing. That is the fact of imperfect human practice.
But the ideal of science is that everyone's idea does matter, or, if you like (though I find it pessimistic), that everyone's ideas don't matter. The ideas of the most untrained novice have exactly as much, or as little, scientific weight as those of the most expert, practiced, and credentialed scientist. This is distinct from the sociological weight of an idea: the scientific community is more likely to listen to the expert, practiced, and credentialed scientist than to the novice. But the quality of a scientific idea is intrinsic to the idea, not to who has it.
I generally agree, though I think calling it the "ideal of science" goes too far. It's more the ideal of democracy.
> imperfect human practice
Whether human social habits affect it or not (I agree they probably do), it would be impossible to spend time examining every amateur idea. And if you see the quality of many amateur ideas - even in a relatively sophisticated population like HN - the payoff gets worse.
That seems awfully like an appeal to authority. Your parent comment doesn't just vaguely snipe, but points out reasons this should have been expected. Those reasons could potentially not be valid, or not present the whole picture, but "the researchers are from Stanford" doesn't rebut them.
I didn't know that! Is it announced somewhere, even buried deep in release notes, or just one of those things that they decided silently to enshittify?
Oh man. I used PostScript a ton when I worked at hp 20 years ago. It's actually a pretty great language, like lisp/scheme but I found it to be more approachable somehow. Maybe because it's postfix instead of prefix?
Anyway, it had several fatal flaws. I don't think it could handle images natively, so instead it encoded them as vectors and those files took up MB. It probably just needed a metaphor like iframe.
I remember when Apple switched to the PDF engine in Quartz in preparation for OS X in the late 90s, I thought it was a mistake then. The QuickDraw it was replacing was actually quite good, in some ways the epitome of C-style rendering. And Cocoa was refreshing at first (it handled stuff like palettes and gamma in a data-driven way instead of through leaky abstractions) but without a way to transition off QuickDraw, it felt like more busywork that had to be done just to keep up.
Apple seems to have lost its academic roots, and suffers for it now. Or I should say, its customers suffer while it grosses almost half a trillion dollars per year. At least with vibe coding we can just whip up a Preview app in an afternoon, so maybe none of this matters anymore.
> Apple seems to have lost its academic roots, and suffers for it now. Or I should say, its customers suffer while it grosses almost half a trillion dollars per year. At least with vibe coding we can just whip up a Preview app in an afternoon, so maybe none of this matters anymore.
Eh, I'm with Apple on this one: we can just use Ghostscript. Apple's move effectively forces the few applications that need to use PostScript on macOS to migrate from a proprietary PostScript implementation to an OSS one, which strikes me as ultimately a good thing.
> .. with vibe coding we can just whip up a Preview app
why deflate your own position with this (worthless-untrue-spineless) statement? Which library is doing the work? who writes that library and maintains it?
that was a real product with ordinary thousands of hours of skilled coding in there.. That is certainly the part that is doing work. Secondly someone really knows what they are doing to slip in those architectural layers / shims / pipes .. Very impressive IMHO
Yes, PostScript is a great general purpose high level programming language, kind of like a cross between Forth and Lisp, but a lot more like Lisp, with its polymorphic homoiconic data structures that were essentially JSON.
>PostScript is kind of like a cross between Forth and Lisp, but a lot more like Lisp actually. And its data structures, which also represent its code, are essentially s-expressions or JSON (polymorphic dicts, arrays, numbers, booleans, nulls, strings, names (interned strings), operators (internal primitives), etc.)
>Kragen is right that PostScript is a lot more like Lisp or Smalltalk than Forth, especially when you use Owen Densmore's object oriented PostScript programming system (which NeWS was based on). PostScript is semantically very different and much higher level that Forth, and syntactically similar to Forth but uses totally different names (exch instead of swap, pop instead of drop, etc).
>You're welcome! OOPS (Object Oriented PostScript ;), I meant to say that PostScript and Lisp are homoiconic, but Forth is not. The PSIBER paper on medium goes into that (but doesn't mention the word homoiconic, just describes how PS data structures are PS code, so a data editor is a code editor too).
The Shape of PSIBER Space: PostScript Interactive Bug Eradication Routines — October 1989:
>PostScript is often compared to Forth, but what it lacks in relation
to Forth is a user-extensible compiler. You can write your own
PostScript control structures and whatnot, like case and cond, to
which you pass procedures as arguments on the stack, but the
PostScript scanner is not smart -- but there is no preprocessing done
to the PostScript text being read in, like the way immediate words in
Forth can take control and manipulate the contents of the dictionary
and stack while the text source is being read in and compiled, or like
the way Lisp macros work. This is one of the things I would like to
be able to do with something like LispScript.
>"Lisp is the language for people who want everything, and are willing to pay for it." -Russell Brand (the old school Lisp hacker "wuthel" from MIT, not the crazy MAGA rapist)
If you want to efficiently implement a PostScript interpreter with rendering in the web browser (or node), you just have to reach for the canvas 2d rendering context, which is essentially the full PostScript stencil/paint imaging model upgraded to the Porter/Duff compositing model with alpha channels, but without the user defined font rendering and halftoning machinery (which you could implement on top of it).
PostScript has always had the black and white "image" and "imagemask" operators, but they are clumsy, don't support any kind of image processing, and you have to use "readhexstring" to read hex images, but later versions support color images.
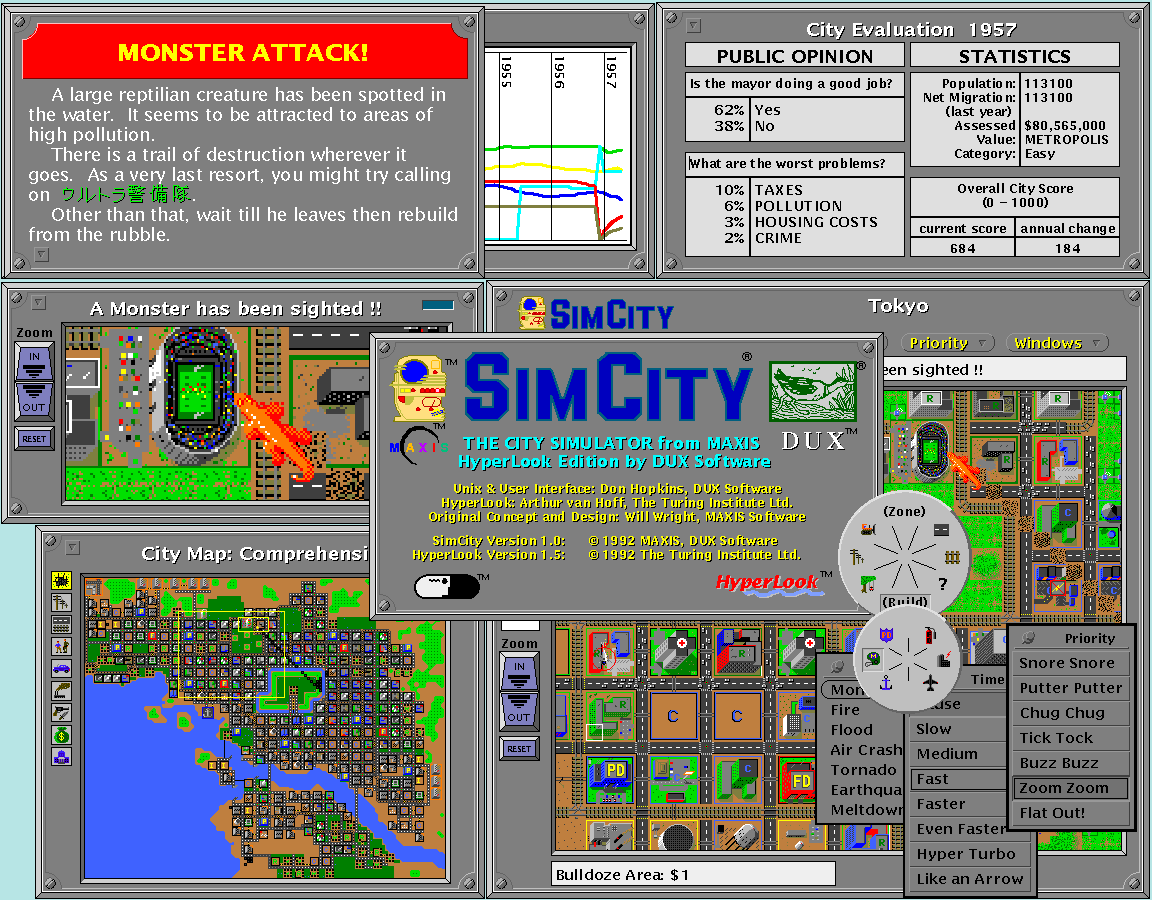
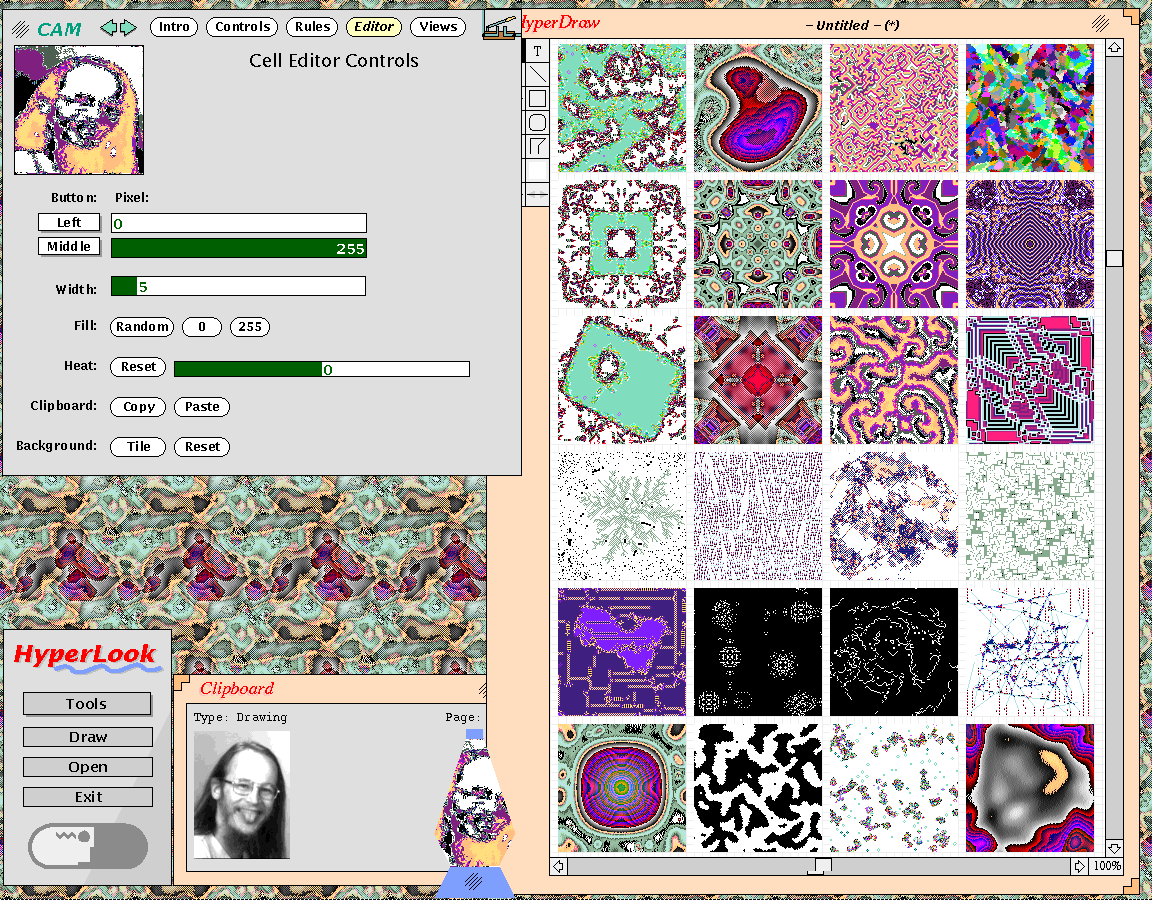
NeWS has "readcanvas" to directly read binary Sun raster files (including color) from files and over the network. It also had memory mapped canvases, which I used for the HyperLook version of SimCity so the C simulator engine could efficiently render the tiles and map views with overlays into memory, and NeWS could scale and render them quickly. I also used memory mapped canvases for my NeWS/HyperLook cellular automata machine, which was implemented in C and scaled and rendered and had a real time painting UI implemented in NeWS PostScript (the client and server took turns "owning" the pixels by ping-ponging messages over the localhost network, so each could draw into the cells in turn, and you could render PostScript directly into the 8-bit color cells for interesting effects, melt people's faces, and clip them on the screen to a window in the shape of a lava lamp).
The Apple PostScript printer drivers used (and Adobe's Blue Book documented) an indirect but efficient hack that tricked the custom halftone rendering machinery into performing a perfect pattern fill (so you could print MacDraw files, etc).
DonHopkins on March 13, 2020 | parent | context | favorite | on: Finding Mona Lisa in the Game of Life
Error diffusion dithering would work very well as initial conditions for many cellular automata rules like Life, especially counting rules (which life is) that stay alive with intermediate numbers of neighbors.
Conway's Life stays alive with 2 or 3 neighbors out of 9, or 2/9 .. 3/9, so gray scales between 22% .. 33% would be the most active.
Halftone screens would have different results, but their regularity might work well with certain CA rules and screens.
PostScript gives you a lot of control over the halftone screen definition.
Halftone screens can use any kind of repeating pattern, there just has to be the proper ratio of white to black pixels to make it look the right brightness. You could even design a set of halftone screen patterns that were precisely matched with a particular cellular automata rule to produce interesting fertile or static patterns. And you can even use any arbitrary pattern for each level, even if they aren't the right brightness, for aesthetic reasons.
The original PostScript LaserWriter was able to efficiently perform pattern fills to print tiled MacDraw images, by defining a custom halftone screen for each tile pixel pattern, that printed precisely the right pixels when you set just the right gray level: the ratio of on pixels to the total number of pixels in the tile. The spot function basically tells the halftone screen machinery what order to turn the dots on as the gray level goes from 1 to 0 (which results is seamless tiling with nearby gray tiles). Take a look at the PostScript header of an old MacDraw file some time to see the really bizarre code that does that by abusing the "setscreen" operator with a contrived spot function. (That was extremely tricky and gave GhostScript problems for years. The trick is documented in Program 15 page 193 of the awesome PostScript "Blue Book", and it uses a lot of memory! It's one of the coolest tricky PostScript hacks I've ever seen!)
>This program demonstrates how to fill an area with a bitmap pattern using the POSTSCRIPT halftone screen machinery. The setscreen operator is intended for halftones and a reasonable default screen is provided by each POSTSCRIPT implementation. It can also be used for repeating patterns but the device dependent nature of the setscreen operator can produce different results on different printers. As a solution to this problem the procedure, ‘‘setuserscreen,’’ is defined to provide a device independent interface to the device dependent setscreen operator.
>IMPLEMENTATION NOTE: Creating low frequency screens (below 60 lines per inch in device space) may require a great deal of memory. On printing devices with limited memory, a limitcheck error occurs when storage is exceeded. To avoid this error, it is best to minimize memory use by specifying a repeating pattern that is a multiple of 16 bits wide (in the device x-direction) and a screen angle of zero
> Only two of these companies actually needs your location data to function, it's Uber and Lyft.
I disagree that they need my location data. I am perfectly capable of telling them the location where I want a pick-up, and they are perfectly capable of imposing penalties if I incorrectly report it. Just like happened with cabs in the old days, who were somehow able to pick me up without real-time location tracking.
(Not to say that you shouldn't be able to just turn on location tracking if that's what you want to do, but there's no reason that they can't function without it.)
There's a difference between "I am the creator of this content [that I actually didn't create]" and "I am enjoying this content that I did not create." One could argue that it matters, in the latter case, whether you are enjoying the content in a manner with the creator's intention of how you enjoyed it, but, to state one among many possible responses, it is far from clear when I consume media through approved channels that that accurately represents how the creator would prefer I enjoy it.
> This weird command is presented with such a benevolent innocence as if it's the simplest thing in the world.
I think it's a question of context and familiarity. To a vim user, like me and, I assume, ahmedfromtunis, their examples do indeed seem simple and natural. Presumably, to an emacs user, the example you quote (if it's quoted literally—I don't use emacs and can't even tell) is just as natural, and assuming some comfort with emacs is presumably OK in a manual for the software!
I got familiar with vi by reading a book that had the main vi commands listed out. First learnt how to quit without saving changes, the rest was just practice.
> How do you get familiar with the software, if the manual expects you to be an expert in it already?
It's surely to the detriment of the manual if the first sentence on the first page assumes you already know the software, but, if nowhere in the manual can it address expert users, then the manual isn't going to be very useful for expert users—and it should be!
The example confusingly includes some weird markup. It's just saying press `ESC-?` then type "window" to search for window commands. These isn't even valid in modern Emacs. The equivalent is `C-h` followed by `a` then type "window".
> Same thing as using a word processor and printer rather than handwriting a note. Inexcusable.
There is no confusion, when in receipt of something written using a word processor, that it was so written, and people are free to respond accordingly (though, of course, most of us don't care). There is no such certainty with products generated by AI, so it is appropriate responsibly to disclose it.
{kind=link}
{kind=link}
{kind=link}
Nor is "this paper is going to appear in Nature" a reason not to wonder whether there might be something that the authors don't know. The whole point of science is that anyone can make an informed critique and self-evaluation of it, with no necessity of depending on a priesthood to interpret it. You can point out the flaws in giantg2's argument https://news.ycombinator.com/item?id=47995899, but neither the venue of the paper, nor the fact that the argument is directed at laypeople in a forum frequented by laypeople, seems to me inherently to indicate such flaws.
reply